Innovation Economics #1
University of Bozen-Bolzano
May 2025
Today’s roadmap
❓Today’s question:
What are the consequences of AI on productivity, creativity, learning, and trust?⚠️Warning:
The literature is in its infancy — some of these results warrant further study.

AI and productivity: Experiment 1
- The tasks completed by participants were based on their real-life jobs (manager, HR professional, data analyst, marketer, consultant, grant writer). Here are some examples.
Task example: manager

AI and productivity: Experiment 1
Task example: HR professional

AI and productivity: Experiment 1
Task example: Marketer

AI and productivity: Experiment 1
Example of response (HR professional, graded with 2 points out of 7)
AI and productivity: Experiment 1
Example of response (HR professional, graded with 6 points out of 7)
AI and productivity: Experiment 1
Results: Treatment effects on productivity
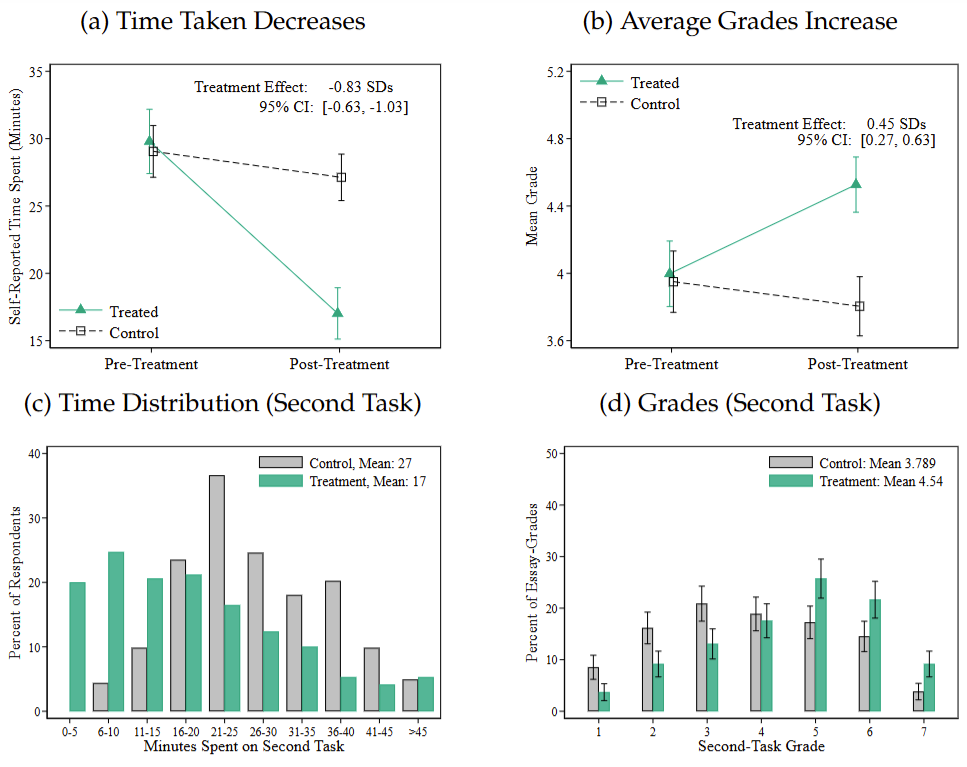
In the Treatment group, time taken for the second task dropped by 10 minutes (37%) compared to the Control group, which took an average of 27 minutes.
Average grades in the Treatment group increased by nearly one point (0.45 standard deviations), with similarly sized improvements in specific areas such as writing quality, content quality, and originality.
The entire time distribution shifted to the left (indicating faster work), while the entire grade distribution shifted to the right (indicating higher quality).
AI and productivity: Experiment 1
Results: Effects on grades and time across the initial grade distribution
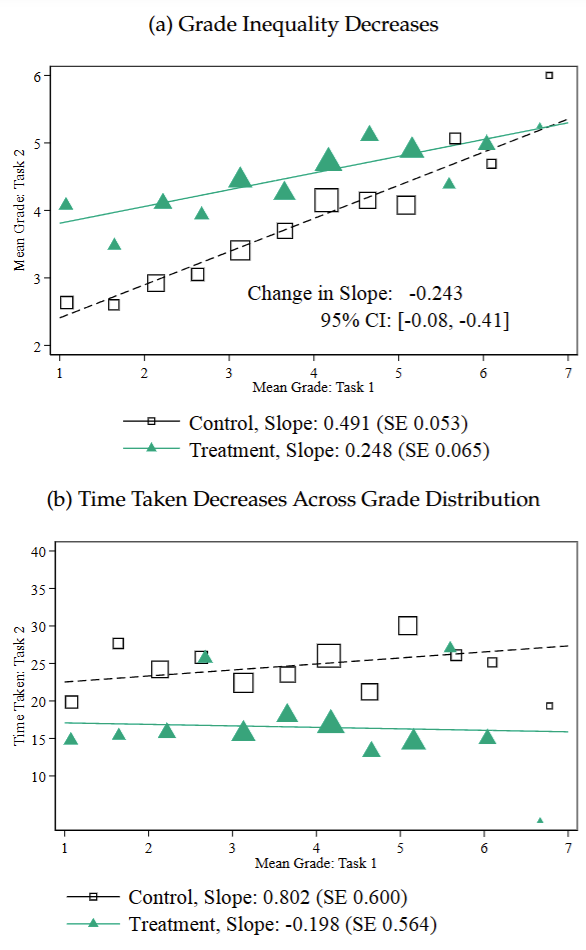
Subjects in the Treatment group who had received a low grade on the first task experienced an increase in grades on the second task compared to subjects in the Control group. Moreover, they reduced the time spent on the second task.
Conversely, subjects in the Treatment group who had received a high grade on the first task maintained a high grade on the second task while substantially reducing their time spent on the task, compared to subjects in the Control group.
AI and productivity: Experiment 1
Results: Effects on task structure
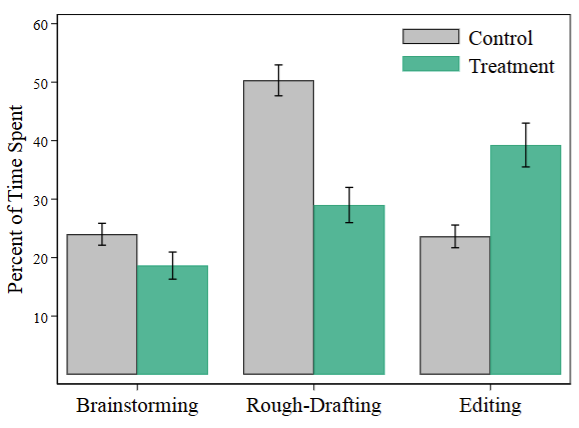
- AI usage significantly changed the structure of writing tasks:
- Prior to the treatment, participants spent about 25% of their time brainstorming, 50% writing a rough draft, and 25% editing.
- Post-treatment, the share of time spent writing a rough draft fell by more than half, while the share of time spent editing doubled.
AI and productivity: Experiment 1
Results: Effects on subjective outcomes
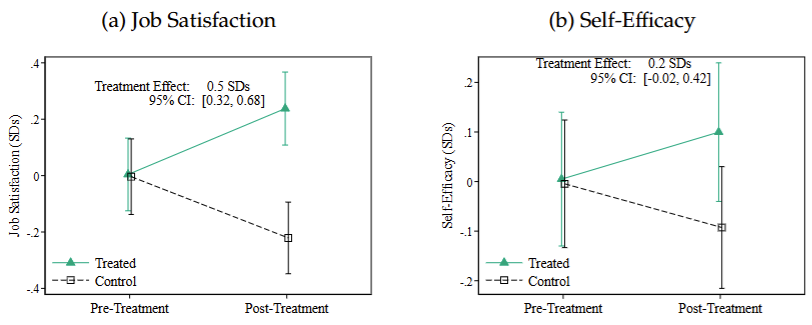
ChatGPT significantly increased satisfaction with the task (by about 0.40 standard deviations) and somewhat increased self-efficacy (by 0.20 standard deviations), despite the fact that participants primarily used it as a substitute for their own effort.
Why do you think this was happened?
AI and productivity: Experiment 2
To substantiate the findings from the first experiment and confirm their external validity, let’s examine the field experiment by Dell’Acqua et al. (2025).
The experiment involved 776 professionals at Procter & Gamble (P&G), a global consumer-packaged goods company.
![]()
AI and productivity: Experiment 2
The tasks
Each individual or team was given one day to develop a new solution addressing a real business need (referred to below as a problem statement) for their business unit.
Each statement was accompanied by relevant market data and additional contextual information.
For confidentiality, the names of specific brand names and company references were removed from the paper.

AI and productivity: Experiment 2
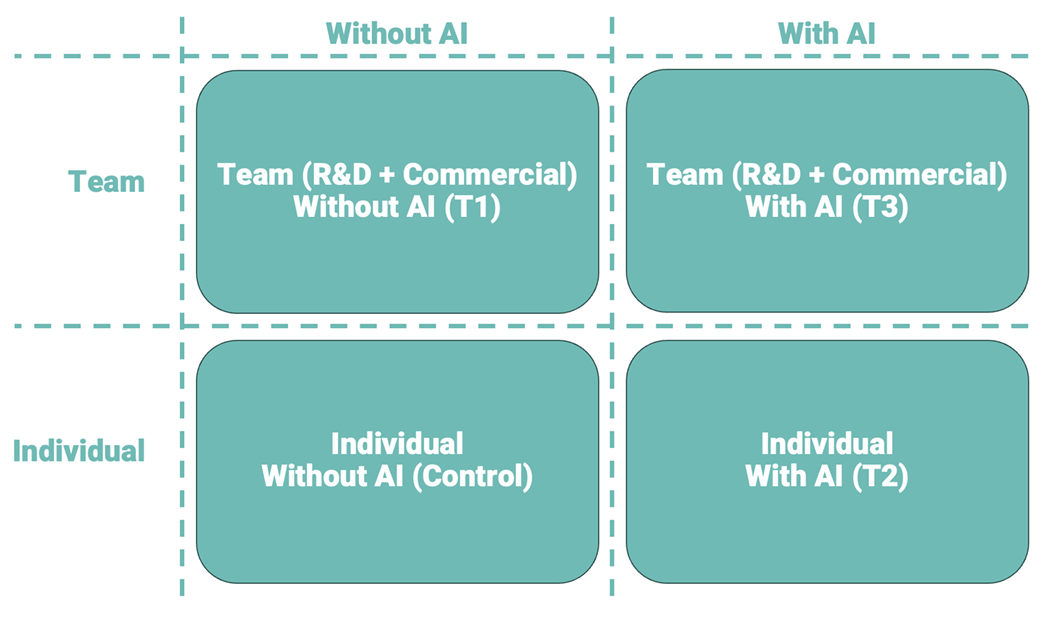
Treatments
- Participants were randomly assigned to one of four conditions according in a \(2 \times 2\) experimental design.
- Control: Individual without AI
- T1: Team without AI
- T2: Individual with AI
- T3: Team with AI
AI and productivity: Experiment 2
Results: Quality of solutions
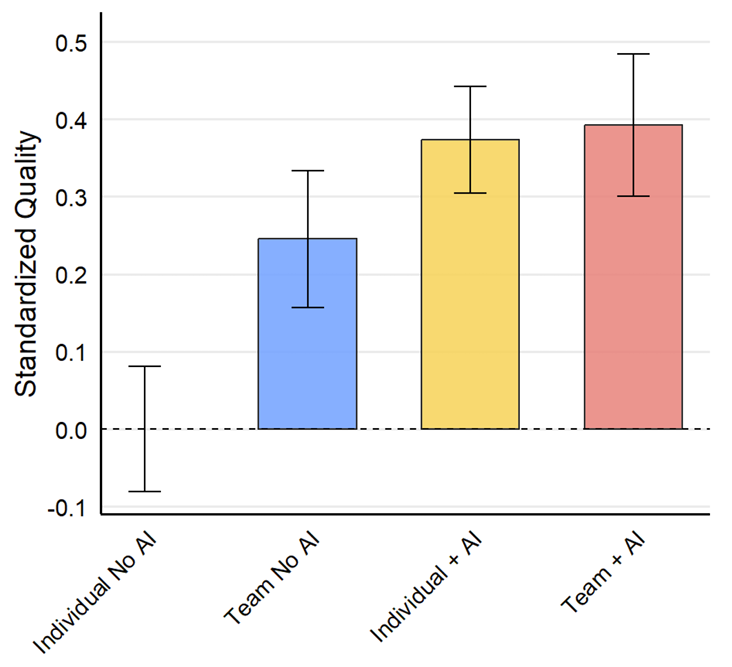
Both teams without AI (T1) and individuals with AI (T2) significantly outperform the Control group.
The quality distributions in T1 and T2 are remarkably similar, suggesting that AI can replicate key performance benefits of teamwork and effectively substitute for team collaboration in certain contexts.
AI and productivity: Experiment 2
Results: Time savings
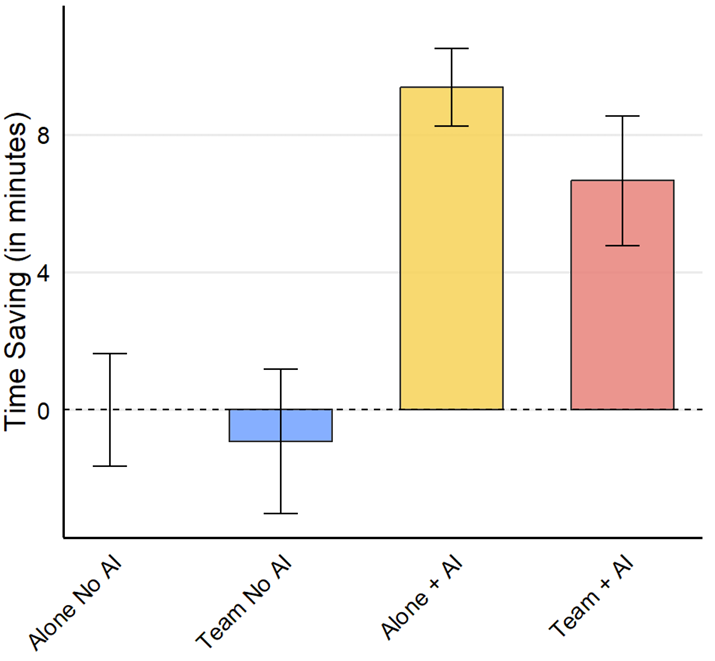
Teams and individuals without AI (Control and T1) spent similar amounts of time on their tasks
The introduction of AI substantially reduced the time spent working on the solution: individuals with AI (T2) spent 16.4% less time than those in the control group, while teams with AI (T3) spent 12.7% less time.
AI and productivity: Experiment 2
Results: Solution quality and expertise
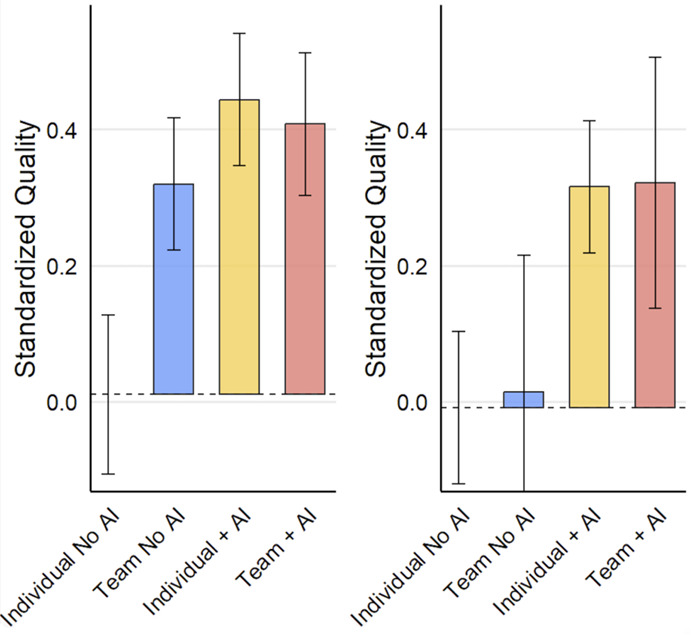
The figure splits the sample between employees for whom product development was a core job task (left-hand panel, ‘core job’) and employees who were less familiar with new product development (right-hand panel, ‘non-core job’).
Without AI, non-core-job employees working alone performed relatively poorly. Even when working in teams, these employees showed only modest improvements in performance.
When given access to AI, non-core-job employees working alone achieved performance levels comparable to those of teams with at least one core-job employee.
This suggests that AI can effectively substitute for the expertise and guidance typically provided by team members who are familiar with the task at hand.
AI and productivity: Experiment 2
Results: Effects on subjective outcomes
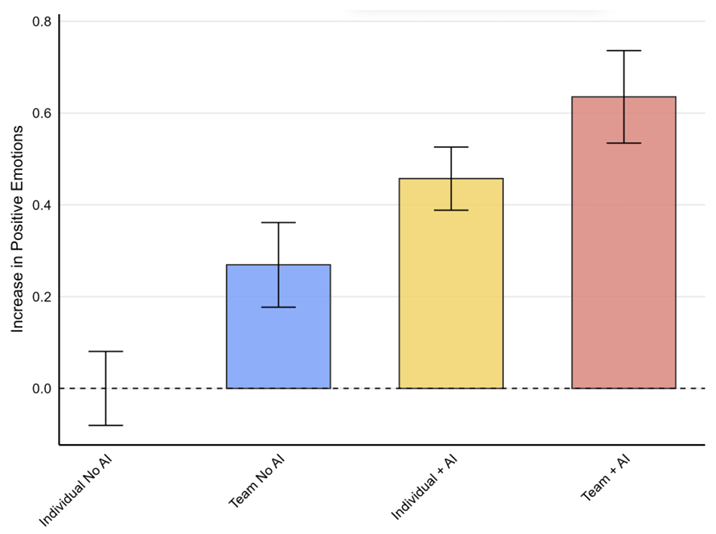
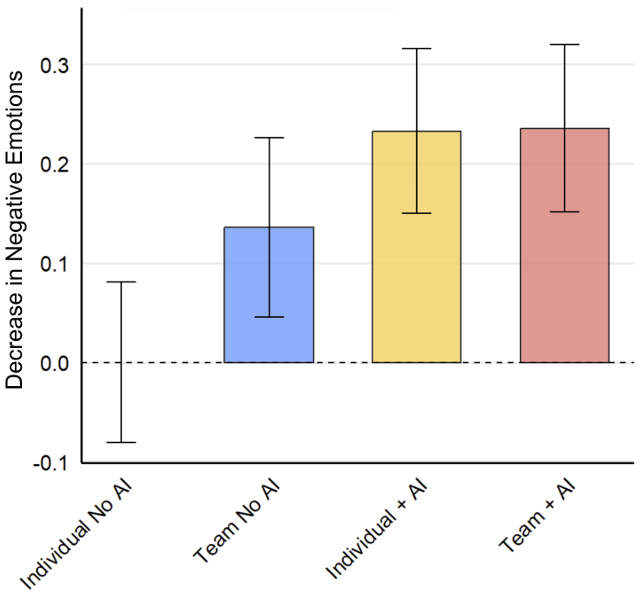
Without AI assistance, individuals working alone (Control) showed lower positive emotions and higher negative emotions compared to those working in teams (T1), reflecting the traditional psychological benefits of human collaboration.
Individuals using AI (T2) reported positive emotions that match or exceed those of team members working without AI (T1).
This suggests that AI can substitute for some of the emotional benefits typically associated with teamwork, serving as an effective collaborative partner even in individual work settings.
AI and productivity: Experiment 2
Results: Retention of AI-assisted Solutions
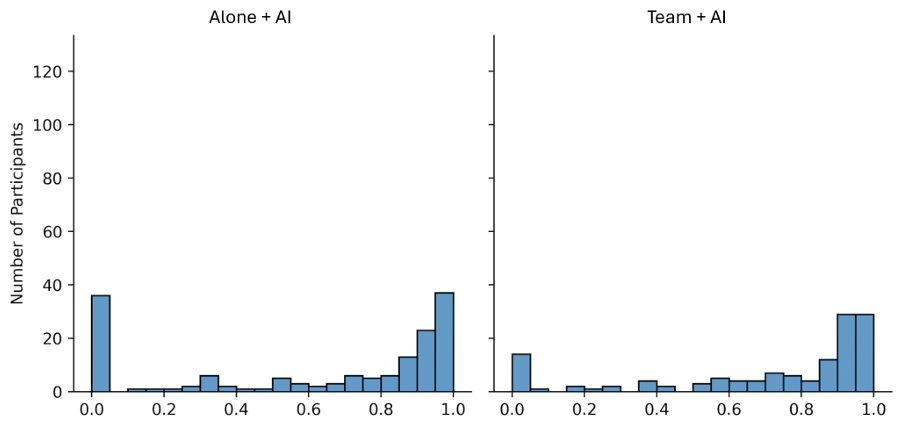
Retention measures the percentage of sentences in the submitted solutions that were originally produced by AI, with a threshold of at least 90% similarity.
For both individuals and groups using AI (T2 and T3), we observe a significant skew towards high retention rates, with many participants retaining more than 75% of AI-generated content in their final solutions.
- This suggests that many participants heavily relied on AI in developing their responses.
- High retention rates do not necessarily indicate passive AI adoption, as participants may engage extensively AI through iterative prompting.
The distribution also shows a significant percentage of participants with zero retention.
This polarized distribution points to two distinct patterns of AI usage: one where participants heavily rely on AI-generated content for their final solutions, and another where AI primarily serves as a collaborative tool for ideation and refinement, rather than direct content generation.
AI and creativity: Experimental evidence
Task example: jungle (Human-only condition)
AI and creativity: Experimental evidence
Task example: jungle (Human with 1 GenAI idea condition after generating the story idea)

AI and creativity: Experimental evidence
Task example: jungle (Human with 5 GenAI ideas condition after generating two story ideas)

AI and creativity: Experimental evidence
Example of story (jungle, Human-only, novelty index = 1.94)

AI and creativity: Experimental evidence
Example of story (jungle, Human-only, novelty index = 5.81)

AI and creativity: Experimental evidence
Example of story (jungle, Human with 1 GenAI idea, novelty index = 2.27)

AI and creativity: Experimental evidence
Example of story (jungle, Human with 5 GenAI ideas, novelty index = 5.87)

AI and creativity: Experimental evidence
Results: Treatment effects on creativity
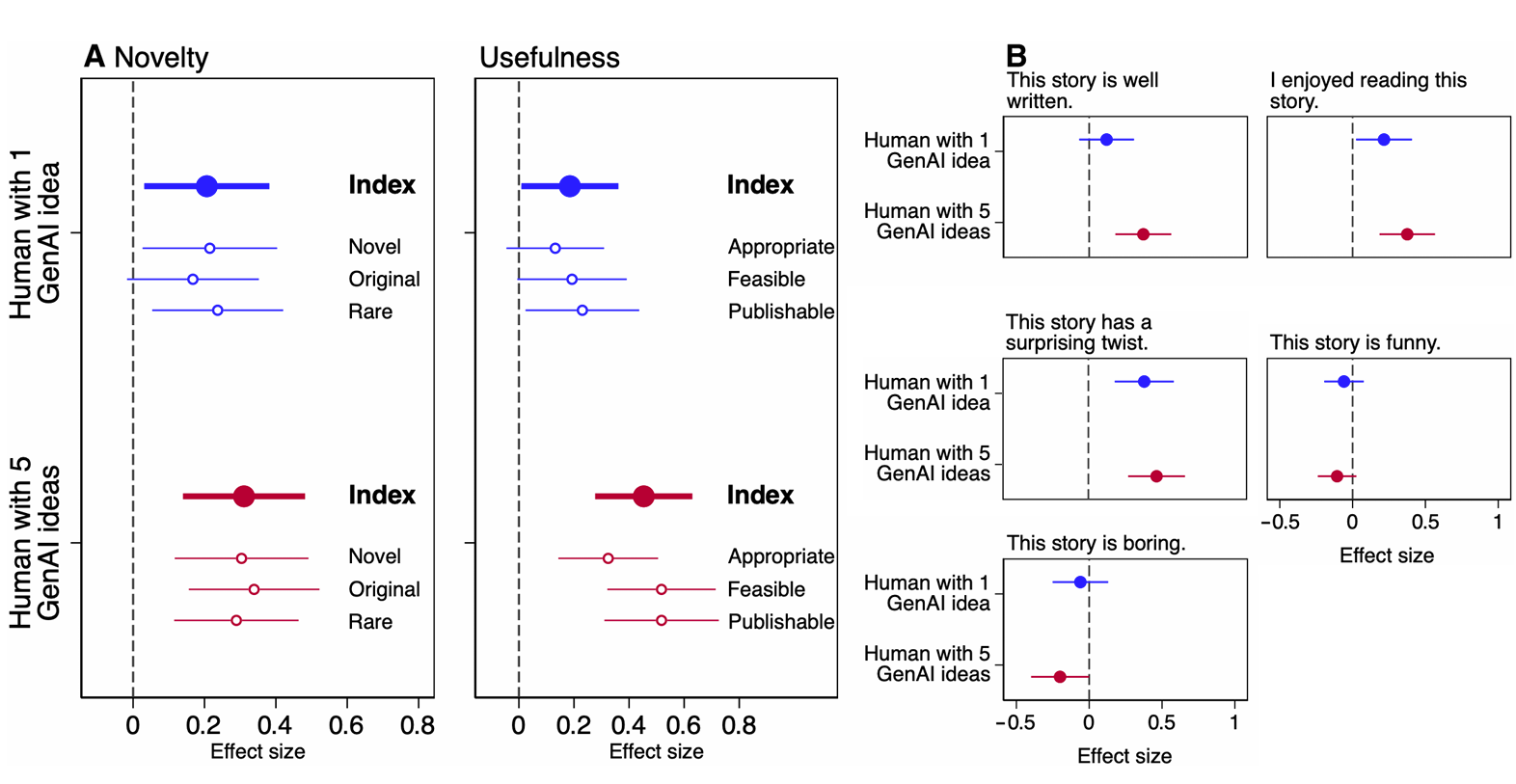
Dashed vertical lines: Human-only condition benchmark.
With respect to novelty, writers in the Human with 1 GenAI idea condition experienced a 5.4% increase over those in the Human-only condition. Writers in the Human with 5 GenAI ideas condition show an 8.1% increase in novelty compared to writers in Human-only .
The usefulness of stories from writers in Human with 1 GenAI idea was 3.7% higher than that of writers in Human-only. Having access to up to 5 GenAI ideas increased usefulness by 9.0% over Human-only and 5.1% over Human with 1 GenAI idea.
Stories written by writers with access to generative AI ideas were significantly more enjoyable, more likely to have plot twists, better written, and less boring. However, they were not funnier.
AI and creativity: Experimental evidence
Results: Treatment effects across the distribution of inherent creativity
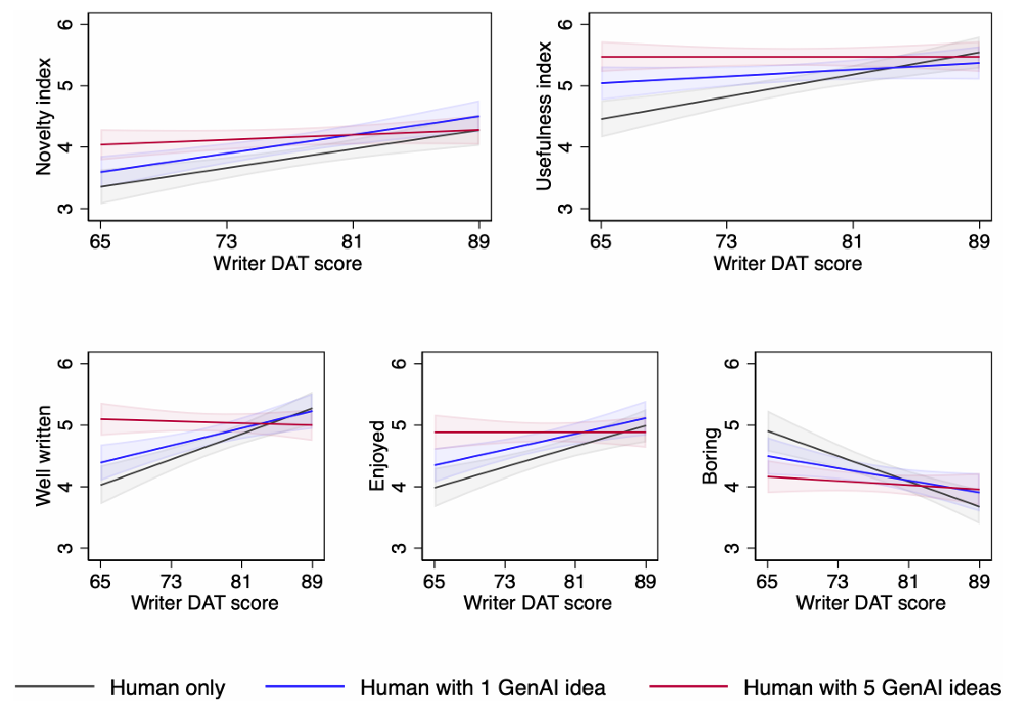
Among the most inherently creative writers (high-DAT score), there was little effect of having access to generative AI ideas on the creativity and quality of their stories.
In contrast, access to generative AI ideas substantially improved the creativity and quality of stories written by less inherently creative writers (low-DAT writers).
- For low-DAT writers, access to one generative AI idea increased a story’s novelty by an average of 6.3%, while access to five generative AI ideas yielded an average improvement of 10.7%.
- Similarly, writers with access to one or five generative AI ideas produced stories that were rated higher for usefulness, with average improvements of 5.5% and 11.5%, respectively.
AI and creativity: Experimental evidence
Results: Similarity of stories
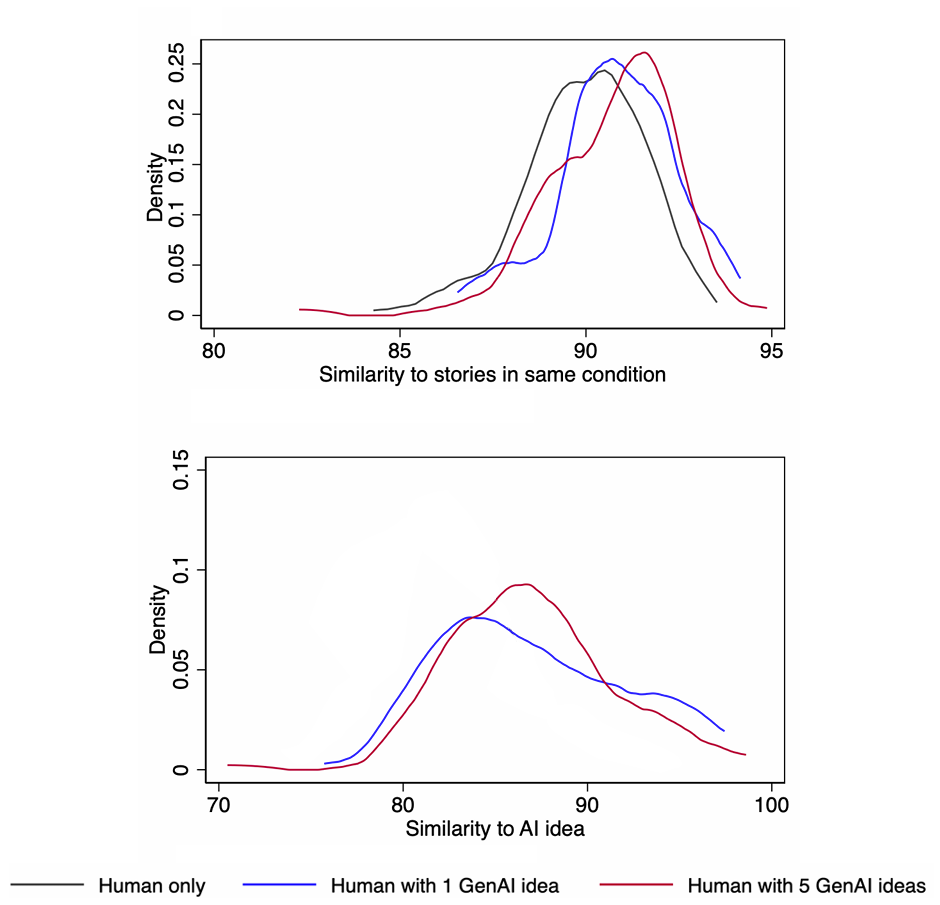
Distributions shifted to the right indicate higher similarity.
Access to generative AI ideas made stories more similar to the average of other stories within the same condition.
The greater the number of available story ideas, the more similar the stories tended to be to the AI-generated idea.
AI and learning: Experimental evidence
The AI tool
AI and learning: Experimental evidence
The AI tool: GPT Base
AI and learning: Experimental evidence
The AI tool: GPT Tutor
AI and learning: Experimental evidence
Prompts: GPT Base vs. GPT Tutor

AI and learning: Experimental evidence
Results: Treatment effects on learning
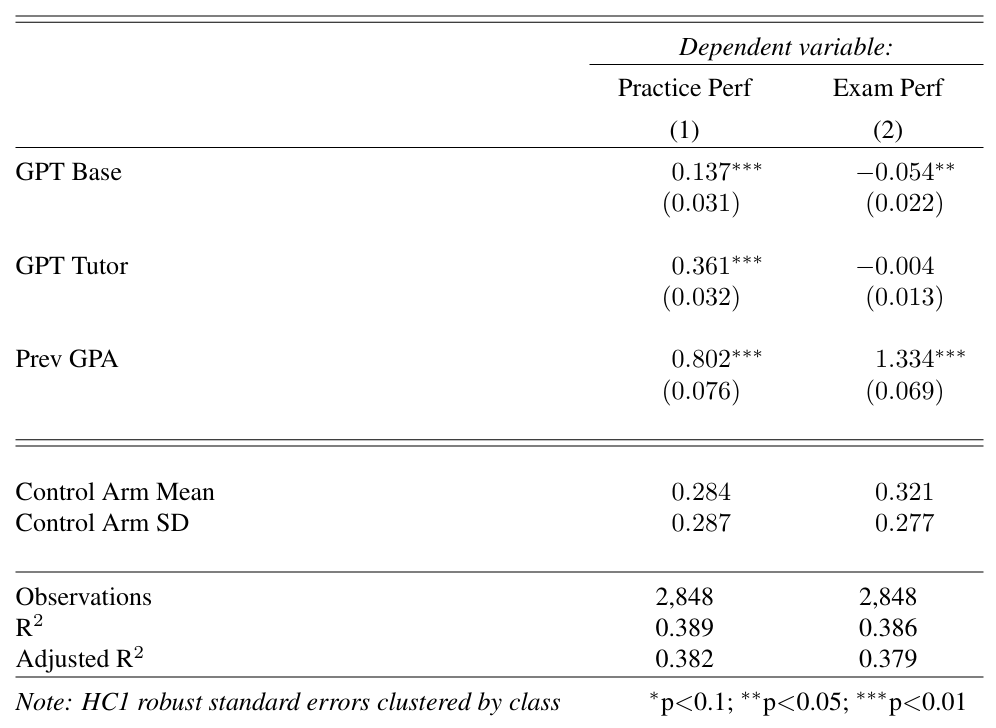
The coefficients on GPT Base and GPT Tutor measure changes in the outcome variables relative to the Control group, which serves as the omitted reference category.
Additional controls: session, grader, grade level, and teacher fixed effects.
Average performance on practice problems in GPT Base and GPT Tutor significantly exceeded that of the Control group by 0.137 and 0.361 points, respectively. The Control group, which only had access to textbooks, had a mean score of 0.28.
In the subsequent unassisted exam, student performance in GPT Base significantly declined by 0.054 points relative to the Control group.
Conversely, performance in GPT Tutor was not significantly different from performance in the Control group.
AI and learning: Experimental evidence
Results: Students’ perception
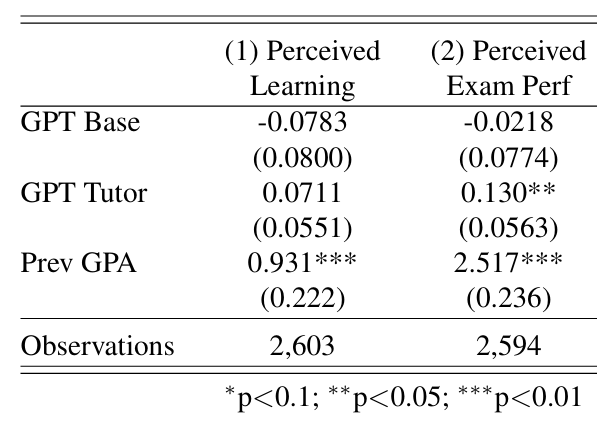
Additional controls: session, grader, grade level, and teacher fixed effects.
Students’ self-reported perceptions of the AI tool’s impact on their exam performance and learning were overly optimistic.
Although students in GPT Base performed worse on the exam than those in the Control group, they did not perceive themselves as having performed worse or learned less.
Similarly, while students in GPT Tutor did not outperform those in the Control group on the final exam, they believed they had performed significantly better.
AI and learning: Experimental evidence
Results: AI-human interactions
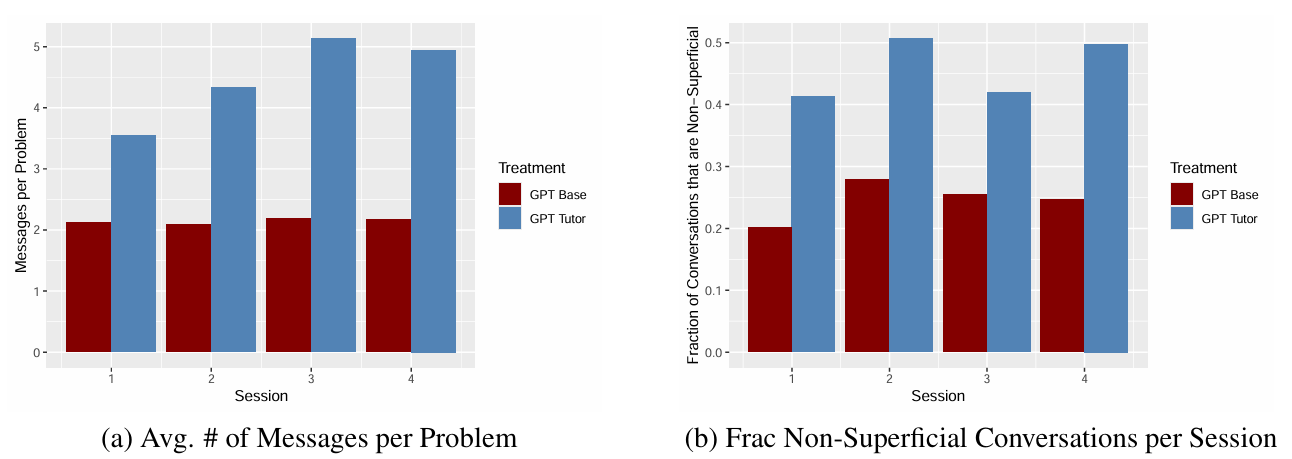
The left-hand figure shows the average number of messages per problem sent by students to the AI tool in each session, which is significantly higher in GPT Tutor than in GPT Base.
The right-hand figure shows the average percentage of non-superficial questions asked by students in each session. In GPT Base, only a small fraction of conversations are non-superficial, indicating that most students used the AI tool primarily to obtain solutions.
In contrast, a significant fraction of students in GPT Tutor engaged with the tool in a more substantive way.
AI and learning: Experimental evidence
Wrap-up
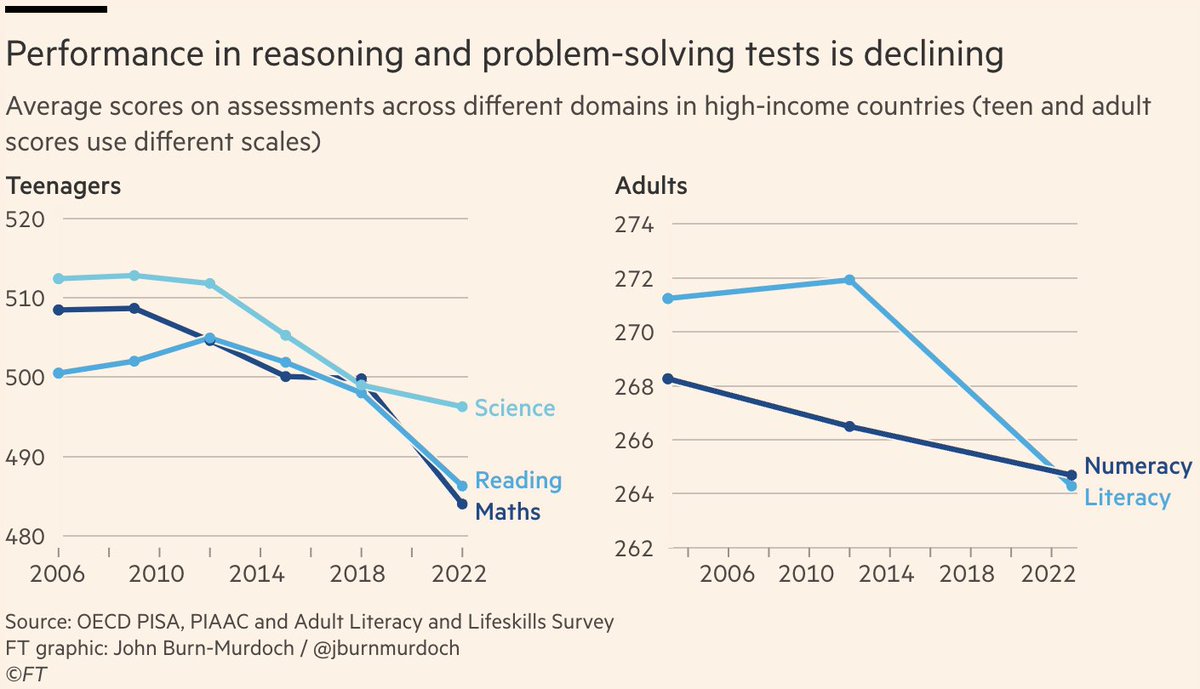
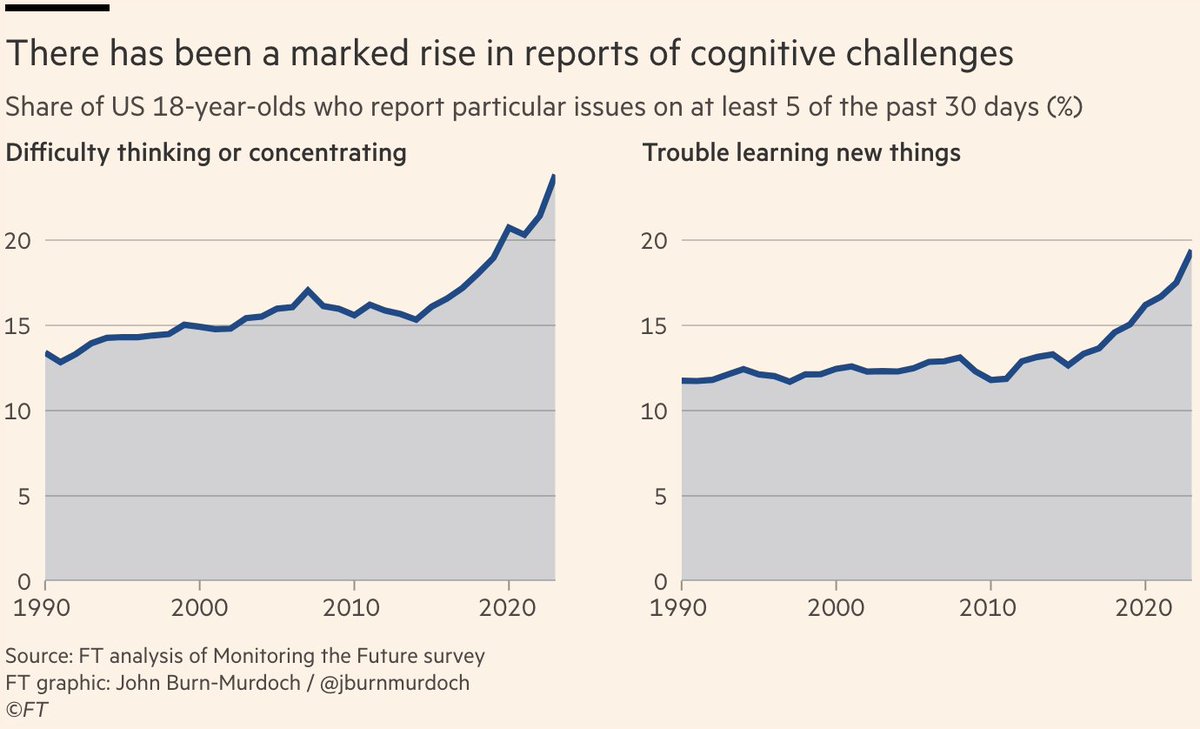
It seems that many students use GPT as a replacement for their own reasoning, rather than as a tool to enhance it.
This is concerning, especially given that human reasoning and problem-solving skills were already in decline even before the advent of AI.
The minimum effort game (cont’d)
Due to the multiplicity of equilibria, people often fail to coordinate on the most rewarding equilibrium (that is the equilibrium in which all players choose the highest effort level).
Leadership has been proved to be effective in improving coordination by sending a signal.

AI and coordination: Experimental evidence
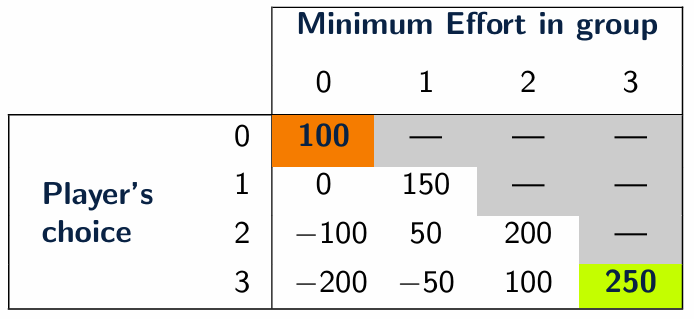
The game
In the experiment, each group member chose an effort level between 0 (lowest) and 3 (highest).
The reward (payoff) of each participant was given by the table below.
![]()
AI and coordination: Experimental evidence
Design
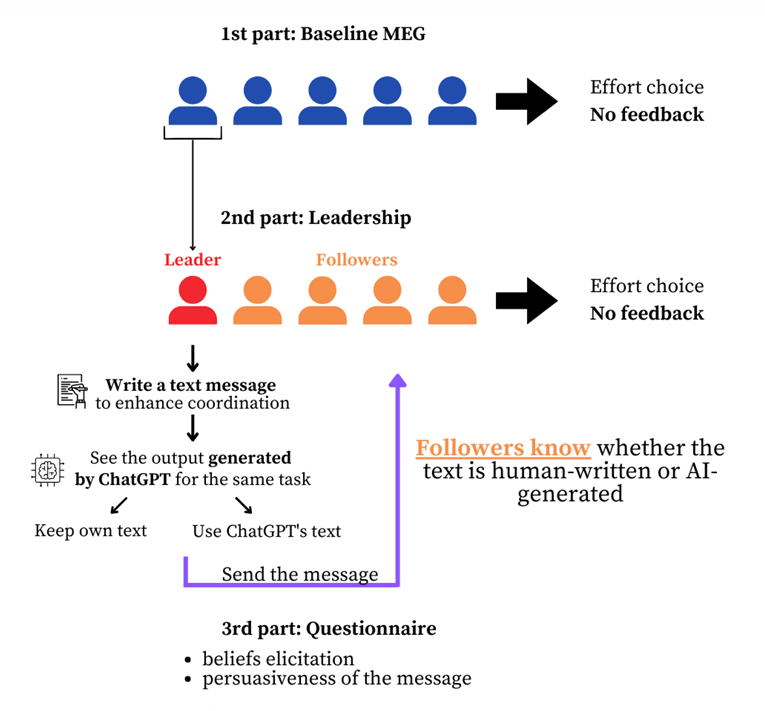
- The experiment consisted of three phases:
Participants played the minimum effort game with no leader/follower distinction and without receiving any feedback about the outcome of the interaction.
This served as a baseline against which to measure the results.
One participant per group was randomly selected to be the leader. The leader chose an effort level and wrote a message to improve coordination.
After writing their message, the leader saw a message generated by ChatGPT for the same purpose and could choose whether to use ChatGPT’s message or keep their own.
Followers knew whether the message was human- or AI-generated. Each follower simultaneously chose their effort level after reading the message, without directly observing the leader’s effort choice.
A questionnaire was administered to participants to measure the persuasiveness of the signal and their beliefs about other group members’ behaviour.
AI and coordination: Experimental evidence
- Only 12.7% of leaders chose to send the AI-generated message.
Example of AI-written message

AI and coordination: Experimental evidence
Example of human-written message
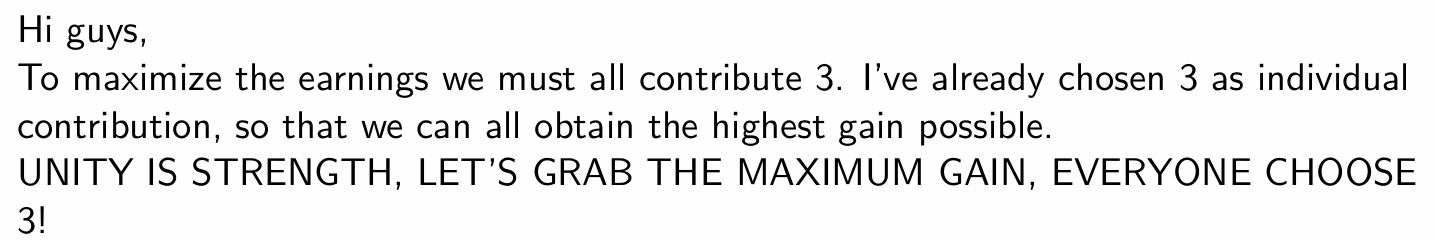
- Question: Which message do you think is more persuasive? Would you exert high effort in both cases, in only one case, or in neither case? Why?
AI and coordination: Experimental evidence
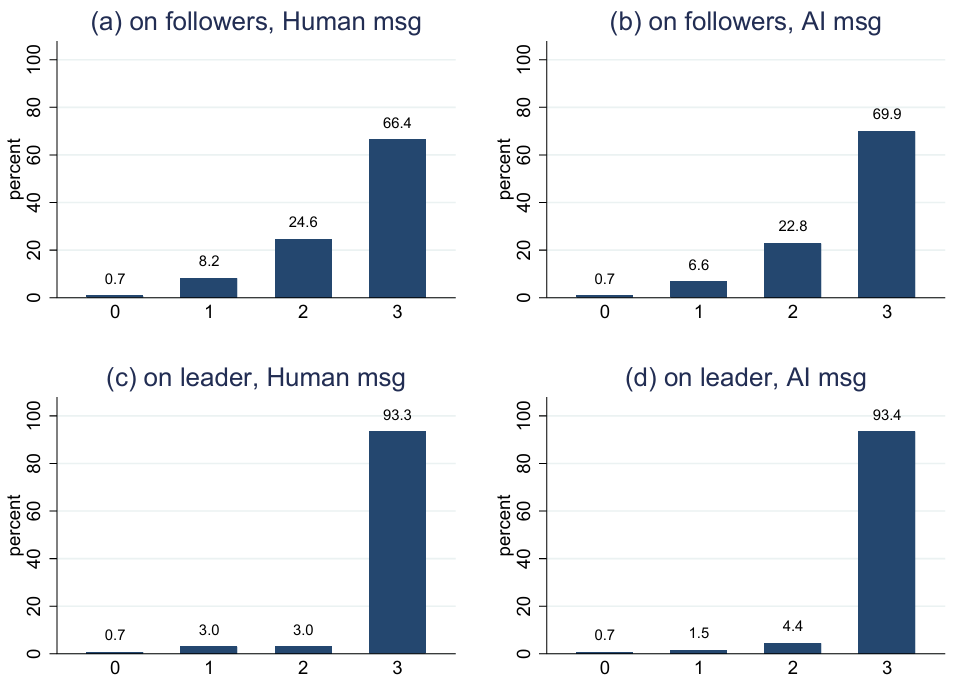
Results: Effort choices
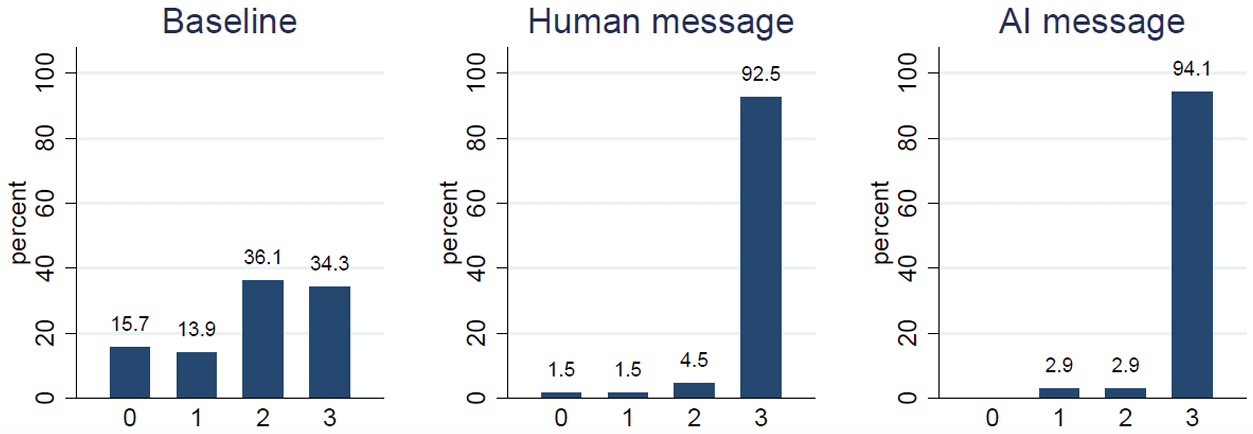
Do followers react differently to human-written and AI-generated messages? Short answer: No.
No significant difference between the Human message and AI message conditions.
Both signaling conditions (Human message and AI message) resulted in significantly higher coordination compared to the Baseline.
AI and coordination: Experimental evidence
Results: Persuasiveness of messagges
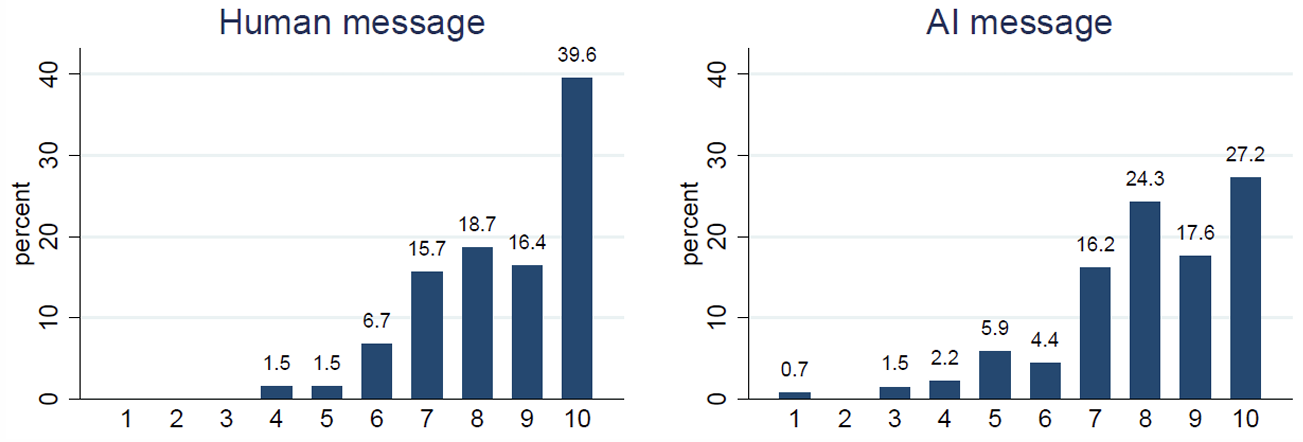
- On average, human-written messages were more persuasive than AI-generated messages…
AI and coordination: Experimental evidence
Results: Beliefs about others’ effort
…but the difference in persuasiveness did not significantly impact followers’ beliefs about others’ effort choices.
That is, followers did not appear to exhibit AI aversion.
Moreover, on average, leaders who chose to send an AI-generated message did not differ in behaviour or beliefs from leaders who sent the message they had written.